
Why Custom Queries?
The process engine offers a pretty straightforward and easy to use Java Query API. If you want to build a task list you just write something like this:
@Inject
private TaskService taskService;
public List<Task> getAllTasks() {
return taskService.createTaskQuery().taskAssignee("bernd").list();
}Easy as it is, there are basically two catches:
- You can only build queries that the API supports.
- You cannot add constraints on your domain objects.
Let us give you a simple use case example, which we implemented in the custom-queries example:
- You have a process variable “customer” holding the customerId
- You have your own entity “Customer” with all the details
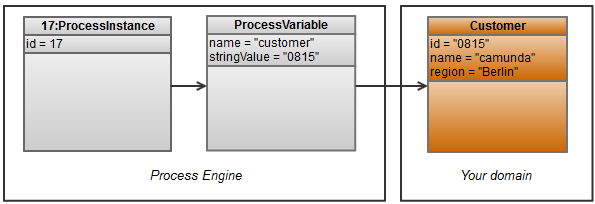
So far, a pretty common situation (please note that the object diagram has been simplified to show the relevant aspects and doesn’t precisely correspond to the implementation classes). What would be easy now is to query all process instances for a customer:
@Inject
private TaskService taskService;
public List<Task> getTasks() {
return taskService.createTaskQuery().processVariableValueEquals("customer", "0815").list();
}But imagine you want to query
- All tasks for a certain region (which is part of your domain, not the process engine database)
- All tasks for customer 0815 or 4711 (the query API always assumes AND and does not support OR)
How to do this?
Possible Solution Approaches
In order to solve the requirements stated in the introduction, we can think of a couple of possible approaches:
- Something we see very often is what we call the “naive” implementation, the easiest way you can think of: use the existing query capabilities and add an own filter to your Java code. This is easy to write for any Java developer. However, it normally queries too much information from the Process Engine’s database and therefore might cause serious performance issues. Last but not least it heavily depends on internal implementation which can change: not recommended.
- Write custom SQL code to do your own queries: possible, but you have to mess around with SQL yourself: not recommended.
- Leverage MyBatis for your custom queries: That is actually a really powerful approach and our recommendation: see the [example below]([relref “#custom-mybatis-queries”]).
- Use JPA: We experimented with JPA mappings for the core engine entities to allow JPA queries. If these mappings exist and you can use them in your own application combined with your own JPA stuff, then it is a possible approach. However, you have to maintain the JPA mappings yourself which involves a lot of work and we have already experienced problems with it in the past, so, basically: not recommended.
- Add redundant information, an easy, but often sufficient, approach to improve queries, which doesn’t need a lot of understanding of the persistence implementation:
- Add process variables for all query parameters. In our example that would mean to add the region as its own process variable. This approach is recommended.
- Add process information to the domain mode. In our example this could mean to add a separate entity task which is synchronized with the process engine task management. This is possible but requires some work which must be done carefully to make sure that the process engine and your domain objects are always in sync.
- Add a materialized view that joins the required database tables into one flat table.
Custom MyBatis Queries
Precondition: In order to use your own MyBatis (or all types of SQL) queries, your domain data and the process engine data must be stored in the same database. Otherwise you cannot technically construct a single SQL query, which is our goal in terms of performance optimization. If you have separate databases, discuss if you really need them (which is the case less often than you think). If the answer is ‘yes’ or you even work with entities only over remote service interfaces, you have to “fall back” to the redundant information approach. Maybe you can use your own entities for that redundant information.
Warning: Writing your own MyBatis queries means that you rely on the internal entity / database structure of the process engine. This is considered quite stable (as otherwise we would have to provide extensive migration scripts), but there is no guarantee. Therefore, please check your MyBatis queries on any version migration you do. This can be skipped if you have good test coverage from automated unit tests.
The following solution is implemented in the custom-queries example, where you will find a complete working example. The code snippets in this article are taken from that example.
In order to add your own MyBatis queries, you have to provide a MyBatis XML configuration file. This file can not only contain SQL commands but also mappings from relational data to Java Objects. The question is how to make MyBatis use our own configuration file, when MyBatis is already set up during the process engine startup? The easiest solution is described here. This approach leverages the existing infrastructure to access MyBatis, including connection and transaction handling, but starts up a completely separate MyBatis Session within the Process Application. This has two big advantages (and no real disadvantage):
- No extensions necessary in the engine configuration (this improves maintainability)
- The MyBatis Session is handled completely within the Process Application, which means that, e.g., classloading works out-of-the-box. This also ensures that the configuration doesn’t intervene with any other Process Application.
In order to do this, we start up a very special Process Engine which only does the MyBatis handling, we can ensure this by overwriting the init method. We also overwrite a hook which gets the name of the MyBatis configuration file:
public class MyBatisExtendedSessionFactory extends StandaloneProcessEngineConfiguration {
private String resourceName;
protected void init() {
throw new IllegalArgumentException("Normal 'init' on process engine only used for extended MyBatis mappings is not allowed.");
}
public void initFromProcessEngineConfiguration(ProcessEngineConfigurationImpl processEngineConfiguration, String resourceName) {
this.resourceName = resourceName;
setDataSource(processEngineConfiguration.getDataSource());
initDataSource();
initVariableTypes();
initCommandContextFactory();
initTransactionFactory();
initTransactionContextFactory();
initCommandExecutors();
initSqlSessionFactory();
initIncidentHandlers();
initIdentityProviderSessionFactory();
initSessionFactories();
}
/**
* In order to always open a new command context set the property
* "alwaysOpenNew" to true inside the CommandContextInterceptor.
*
* If you execute the custom queries inside the process engine
* (for example in a service task), you have to do this.
*/
@Override
protected Collection<? extends CommandInterceptor> getDefaultCommandInterceptorsTxRequired() {
List<CommandInterceptor> defaultCommandInterceptorsTxRequired = new ArrayList<CommandInterceptor>();
defaultCommandInterceptorsTxRequired.add(new LogInterceptor());
defaultCommandInterceptorsTxRequired.add(new CommandContextInterceptor(commandContextFactory, this, true));
return defaultCommandInterceptorsTxRequired;
}
@Override
protected InputStream getMyBatisXmlConfigurationSteam() {
return ReflectUtil.getResourceAsStream(resourceName);
}
}This allows us to access our own queries (we will show this in a moment) from our MyBatis session by constructing an Command object:
Command<List<TaskDTO>> command = new Command<List<TaskDTO>>() {
public List<TaskDTO> execute(CommandContext commandContext) {
// select the first 100 elements for this query
return (List<TaskDTO>) commandContext.getDbSqlSession().selectList("selectTasksForRegion", "Berlin", 0, 100);
}
};
MyBatisExtendedSessionFactory myBatisExtendedSessionFactory = new MyBatisExtendedSessionFactory();
myBatisExtendedSessionFactory.initFromProcessEngineConfiguration(processEngineConfiguration, "/ourOwnMappingFile.xml");
myBatisExtendedSessionFactory.getCommandExecutorTxRequired().execute(command);This is already everything you need. See the example usage in TasklistService.java.
Now let’s get back to the example from the beginning. We want to query all tasks of customers for a certain region. First of all, we have to write an SQL query for this. Let’s assume that we have the following entity stored in the same Data-Source as the process engine:
@Entity
@Table(name="CUSTOMER")
public class Customer {
@Id
@Column(name="ID_")
private long id;
@Column(name="REGION_")
private String region;
...Now the SQL query has to join the CUSTOMER with the VARIABLES table from the process engine. Here we do an additional trick as once used for another standard problem: We join in ALL process variables to receive them together with the Tasks in one query. Maybe this is not your use case, but it might show you how powerful this approach can be. The full MyBatis Mapping can be found in customTaskMappings.xml.
<select id="selectTasksForRegion" resultMap="customTaskResultMap" parameterType="org.camunda.bpm.engine.impl.db.ListQueryParameterObject">
${limitBefore}
select distinct
T.ID_ as tID_,
T.NAME_ as tNAME_,
T.DESCRIPTION_ as tDESCRIPTION_,
T.DUE_DATE_ as tDUE_DATE_,
...
CUST.ID_ as CUSTOMER_ID_,
CUST.NAME_ as CUSTOMER_NAME_,
CUST.REGION_ as CUSTOMER_REGION_,
VAR.ID_ as VID_,
VAR.TYPE_ as VTYPE_,
VAR.NAME_ as VNAME_
...
from ${prefix}ACT_RU_TASK T
left outer join (select * from ${prefix}ACT_RU_VARIABLE where NAME_= 'customerId' ) VAR_CUSTOMER on VAR_CUSTOMER.EXECUTION_ID_ = T.EXECUTION_ID_
left outer join CUSTOMER CUST on CUST.ID_ = VAR_CUSTOMER.LONG_
right outer join ${prefix}ACT_RU_VARIABLE VAR on VAR.EXECUTION_ID_ = T.EXECUTION_ID_
<where>
<if test="parameter != null">
CUST.REGION_ = #{parameter}
</if>
</where>
${limitAfter}
</select>We will explain the joins briefly: The first two joins check if there is a process variable named “customerId” and join it to the CUSTOMER table, which allows it to add CUSTOMER columns in the select as well as in the where clause, and the last right outer join joins in all existing process variables. There is one catch in that last statement: We now get one row per process variable. Let’s assume we have 10 tasks with 10 variables each, then our result set has 100 rows. This is no problem for MyBatis, it can map this to a Collection as we will see in a moment, but in this case the LIMIT statement we use for paging is applied to the overall result set. So, if we tell MyBatis to get the first 50 tasks, we only get 5 tasks, because we have 50 rows for this. This is not a general problem of the approach described here but a glitch in the SQL query provided, maybe you can think of smarter way to write this?
This brings us to the last piece of code we want to draw your attention to: The Mapping. In order to get the customer data together with the Task information we defined a separate DTO object (DTO stands for Data Transfer Object, it basically means a Java object used as value container). This DTO holds a list of the process variables as well:
public class TaskDTO {
private String id;
private String nameWithoutCascade;
private String descriptionWithoutCascade;
private Date dueDateWithoutCascade;
private Customer customer;
private List<ProcessVariableDTO> variables = new ArrayList<ProcessVariableDTO>();
...Filling these objects with the result set from our Query is now an easy task for MyBatis with this mapping:
<resultMap id="customTaskResultMap" type="org.camunda.demo.custom.query.TaskDTO">
<id property="id" column="tID_" />
<result property="nameWithoutCascade" column="tNAME_" />
<result property="descriptionWithoutCascade" column="tDESCRIPTION_" />
<result property="dueDateWithoutCascade" column="tDUE_DATE_" />
<association property="customer" javaType="com.camunda.fox.quickstart.tasklist.performance.Customer">
<id property="id" column="CUSTOMER_ID_"/>
<result property="name" column="CUSTOMER_NAME_"/>
<result property="region" column="CUSTOMER_REGION_" />
</association>
<collection ofType="org.camunda.demo.custom.query.ProcessVariableDTO" property="variables" column="tPROC_INST_ID_" resultMap="customVariableResultMap"/>
</resultMap>
<resultMap id="customVariableResultMap" type="org.camunda.demo.custom.query.ProcessVariableDTO">
<id property="id" column="VID_" />
<result property="name" column="VNAME_" />
<result property="value" column="VTEXT_" />
</resultMap>We hope that this is somehow self-explanatory, otherwise best take a look at the MyBatis XML configuration reference.
This is all you have to do. Please check out the full code in the example, you can to run it directly on the JBoss distribution. You can easily play around with it to check if it serves your needs or to compare query performance to an implementation you had until now, maybe something similar to the naive implementation we mentioned at the beginning (and be assured: we see that really often out there ;-)).
Performance Experiences
It was really important to us to write this article because sometimes we hear that the process engine performs badly and almost every time this is related to wrongly designed queries. One customer had his project status turned to “dark yellow” (which is close to red) because of these performance issues. This solution improved performance by a factor greater than 10 and fixed paging and sorting issues, bringing the project back on track. So we think everybody should know about it!
